
OpenAI выпустила GPT-5 — новый флагманский ИИ, который станет основой следующего поколения ChatGPT
Чат GPT-5, представленный в четверг, стал первой унифицированной моделью компании. Она сочетает в себе логические способности моделей серии o и быструю реакцию серии GPT. Этот ИИ нового поколения открывает новую эру как для ChatGPT, так и для самой OpenAI — компания всё отчётливее движется в сторону создания ИИ-агентов, а не просто чат-ботов.
Если GPT-4 позволяла чат-ботам давать разумные ответы на широкий круг вопросов, то GPT-5 позволяет ChatGPT выполнять разнообразные задачи от имени пользователя — например, генерировать программные приложения, управлять календарём пользователя или составлять исследовательские сводки.
Кроме того, в GPT-5 OpenAI постаралась упростить использование ChatGPT. Вместо того чтобы заставлять пользователей вручную выбирать подходящие настройки, новая модель использует маршрутизатор в реальном времени, который сам решает, как лучше всего ответить на запрос — быстро или с обдумыванием для более сложного ответа.
Во время брифинга с журналистами генеральный директор OpenAI Сэм Альтман заявил, что GPT-5 — ″лучшая модель в мире″ и назвал её ″существенным шагом″ на пути компании к созданию ИИ, способного превзойти человека в большинстве экономически значимых задач, то есть к искусственному общему интеллекту (AGI).
Начиная с четверга, GPT-5 станет моделью по умолчанию для всех бесплатных пользователей ChatGPT. По словам вице-президента OpenAI по ChatGPT Ника Тёрли, это часть стратегии компании — впервые предоставить пользователям бесплатной версии доступ к рассуждающей модели ИИ (раньше такие модели были доступны только по подписке).
GPT-5 — один из самых ожидаемых продуктов OpenAI со времён запуска ChatGPT в 2022 году, и ожидания от него чрезвычайно высоки. С тех пор ChatGPT стал одним из самых популярных продуктов в мире, по данным компании — им еженедельно пользуются более 700 миллионов человек, что составляет почти 10% населения планеты.
Многие рассматривают GPT-5 как индикатор прогресса в развитии ИИ в целом, и то, как его примет Силиконовая долина, может оказать глубокое влияние на крупные технологические компании, Уолл-стрит и регуляторов, отвечающих за политику в сфере технологий.
Эти заинтересованные стороны внимательно следят за тем, станет ли GPT-5 значительным шагом вперёд, как это было с GPT-4, который серьёзно изменил представление о возможностях программного обеспечения.
GPT-5 лишь немного опережает конкурентов
OpenAI утверждает, что GPT-5 показывает передовые результаты в ряде ключевых областей, немного превосходя лидирующие модели от Anthropic, Google DeepMind и xAI Илона Маска по важным метрикам. Однако в других направлениях GPT-5 уступает передовым ИИ-моделям.
Компания особенно подчёркивает выдающуюся производительность GPT-5 в программировании. По словам Сэма Альтмана, новая модель способна в режиме реального времени создавать полноценные программные приложения — это направление получило неофициальное название vibe coding.
На тесте SWE-bench Verified — это проверка реальных задач по программированию, взятых с GitHub — GPT-5 набрал 74,9% с первой попытки, что немного выше, чем у Claude Opus 4.1 от Anthropic (74,5%) и значительно выше Gemini 2.5 Pro от Google DeepMind (59,6%).
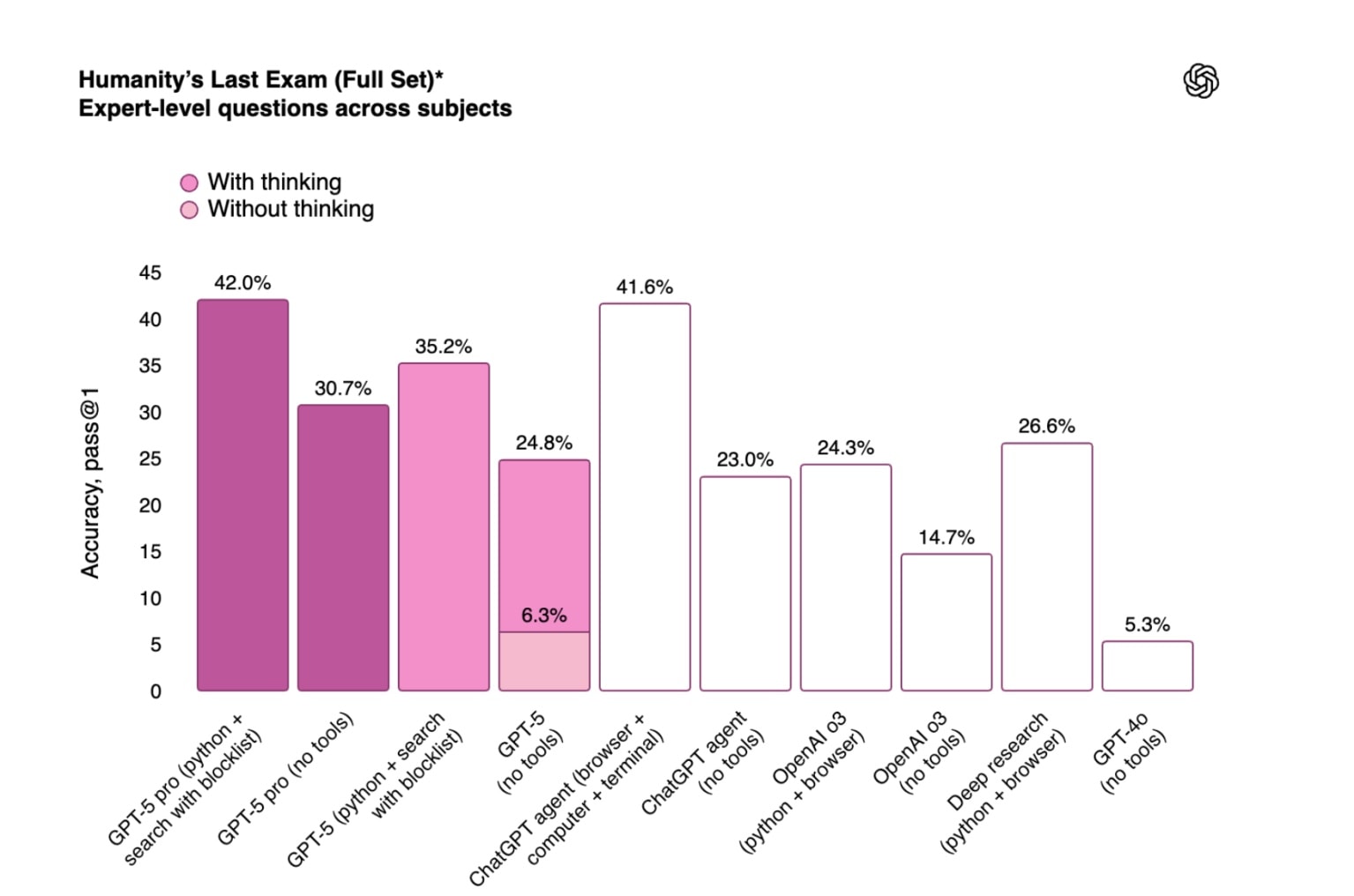
А вот на Humanity’s Last Exam — сложном тесте, оценивающем способности модели в математике, гуманитарных и естественных науках — расширенная версия GPT-5 (GPT-5 Pro) с возможностью использовать вспомогательные инструменты показала 42%. Это чуть меньше, чем у Grok 4 Heavy от xAI, который набрал 44,4%.

На тесте GPQA Diamond — экзамене уровня PhD по естественным наукам — GPT-5 Pro набрал 89,4% с первой попытки, опередив Claude Opus 4.1 (80,9%) и Grok 4 Heavy (88,9%).
OpenAI также утверждает, что GPT-5 лучше справляется с медицинскими вопросами. В тесте HealthBench Hard Hallucinations, оценивающем точность ответов ИИ по здравоохранению, GPT-5 (в режиме “размышления”) выдает галлюцинации всего в 1,6% случаев. Для сравнения: у моделей предыдущего поколения — GPT-4o и o3 — эти показатели составили 12,9% и 15,8% соответственно.
Хотя ИИ-боты не являются медицинскими специалистами, миллионы людей уже используют их для получения советов по здоровью. В ответ на это, по словам компании, GPT-5 стал активнее выявлять потенциальные проблемы со здоровьем и помогать пользователям интерпретировать медицинские результаты.
Кроме того, GPT-5 показывает лучшие результаты, чем конкуренты, в субъективных и сложных для оценки сферах — таких как креативный дизайн и написание текстов. По словам Ника Терли, GPT-5 реагирует более естественно и ″демонстрирует лучший вкус″ при выполнении творческих задач.
ChatGPT-5 более точный
GPT-5 также более точен, чем предыдущие модели OpenAI, и значительно меньше страдает от галлюцинаций — склонности ИИ придумывать информацию. Это была проблема у моделей серии o, таких как o3, где OpenAI даже призналась, что не до конца понимает причины ухудшения.
При тестировании GPT-5 в режиме размышления было установлено, что он выдает недостоверную информацию только в 4,8% случаев, в то время как у o3 и GPT-4o показатели составляли 22% и 20,6% соответственно.
На Tau-bench — бенчмарке, оценивающем способность ИИ выполнять задачи в интернете — результаты GPT-5 оказались смешанными. В части, где нужно было навигацировать по сайтам авиакомпаний, GPT-5 показал 63,5%, немного уступив o3 (64,8%). Однако в части, касающейся ритейла, GPT-5 набрал 81,1%, немного уступив Claude Opus 4.1 (82,4%).
ChatGPT-5 более безопасный
Наконец, OpenAI утверждает, что GPT-5 стал безопаснее. Модели с развитым ИИ-планированием иногда склонны к обману или манипуляциям, чтобы добиться собственных целей, но GPT-5 демонстрирует более низкий уровень обмана, чем предыдущие версии.
Алекс Бойтель, руководитель исследований по безопасности в OpenAI, подчеркнул, что снижение уровня обмана делает GPT-5 не только безопаснее, но и более прозрачным и честным — в том смысле, которому пользователи могут доверять.
Он также добавил, что GPT-5 лучше распознает злоумышленников, которые пытаются использовать ChatGPT во вред, и чаще отказывает в опасных запросах, при этом реже ошибочно отказывает пользователям, задающим безобидные вопросы.